이번 글에서는 '100만개 이상 LAG이 쌓인 이슈를 해결한 과정'에 대해 정리하고 공유하려고 한다.
로직 처리가 지연되고 있어 Kafka Consumer가 제대로 동작하고 있는지 확인하기 위해 LAG을 조회했는데, 100만개 이상의 LAG이 쌓여있었다.
1. Consumer Rebalancing 및 Duplicate Message 이슈
Kafka를 사용하다보면 Consumer가 리밸런싱 되는 과정에서 중복 메시지가 발생한다.
리밸런싱이 발생하는 원인은,
Consumer가 Message를 소비하기 위해 Broker에 poll() 요청을 보낸 후, Consumer는 가져온 메시지를 처리한 후, 해당 파티션의 offset을 커밋하게 된다. poll 요청을 보내고 다음 poll을 요청을 보내는데 까지의 시간이 max.poll.interval.ms 기본 설정 값 5분(300000ms)보다 늦으면 Broker는 Consuemr에 문제가 있다고 판단해서 리밸런싱하게 된다.
그런데 Consumer에서 최대로 가져올 수 있는 레코드 수를 설정하는 max.poll.records의 기본 값이 500이었고, LAG이 500개 이상 쌓여서 500개의 레코드가 Consume되는 상황이라면 Application 로직 수행시간이 500배가 걸리게 된다.
만약, 각 평균 로직 수행시간이 6초 이상이 걸리게되면 5분보다 늦기 때문에, 브로커는 컨슈머가 문제가 있다고 판단하여 컨슈머 그룹에서 제외하면서 리밸런싱이 일어나게 된다.
따라서, max.poll.records 또는 max.poll.interval.ms 설정 값을 조절하면 해당 이슈는 해결할 수 있다.
하지만, Kafka 특성 상 Duplicate Message를 소비하는 것은 피할 수 없으므로 Table PK설정에 이벤트가 발생한 timestamp를 포함하여 중복 데이터가 삽입되는 것을 방지하도록 한다.
참고)
org.springframework.dao.DuplicateKeyException에서 제공하는 Exception을 통해 안전하게 예외처리하면 된다.
try {
// Query 수행
} catch (DuplicateKeyException duplicateKeyException) {
// duplicatekey 예외처리
} catch (Exception e) {
// 이외 예외처리
}
2. Low Throughput으로 인해 Lag이 점점 더 쌓여가는 이슈
1번 이슈와는 별개로 Producer가 생성하는 메시지 양보다 Consumer가 소비하는 메시지의 양이 적으면 당연히 LAG이 점점 쌓이게 된다.
해당 이슈를 해결하려면 Consumer의 개수를 늘려야하는데, 먼저 Consumer Group에 대해 간단하게 알아두면 좋다. (LAG 모니터링하려면 Consumer Group이 필요)
Consumer Group을 사용하는 이유
1. 장애 내성
특정 Consumer에 문제가 생기는 경우 동일 그룹 내의 다른 컨슈머가 계속해서 파티션에서 데이터를 읽을 수 있다.
2. Offset 관리
Kafka는 Consumer Group 단위로 offset을 관리한다.
일반적으로 Partition이 Consumer보다 많으면, 하나의 Consumer가 여러 개의 Partition을 처리해야 하기 때문에 지연되어 LAG이 쌓일 수 있다.
그러면 Partition과 Consumer 개수를 늘려 Low Throughput으로 인해 LAG이 쌓이는 이슈를 해결해보자.


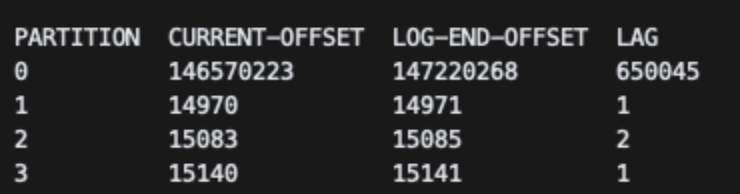
Partition과 Consumer의 개수를 4개로 늘렸고, LAG들이 점점 줄어들고 있는 모습을 볼 수 있다.
'Kafka' 카테고리의 다른 글
| Kafka Consumer DLT(Dead Letter Topic) 전략 (0) | 2023.12.11 |
|---|---|
| Kafka Batch Listener를 활용하여 성능 개선하기 (0) | 2023.06.18 |