해당 글은 우아한 테크캠프 PRO에서 진행된 JPA Hands-on Part 1 강의의 내용을 정리한 내용이다.
JPA 도입 배경
JdbcTemlapte, MyBatis는 객체 그래프를 완성하는게 쉽지 않다.
Spring Data JDBC는 도메인주도설계 영향을 굉장히 많이 받은 프레임워크다.
- 지연로딩, 더티체크 등 영속성과 관련된 기능이 없음
- 무조건 엔티티 save를 호출해야함
JPA
- 객체지향 패러다임과 RDB 패러다임을 중간에서 Java Persistence API
- 현재는 Jakarta Persistence API
- Spring은 JPA의 구현체를 Hibernate 6로 사용
JPA 특징
1. JPA 데이터베이스 스키마 생성 전략
- create, validate, none 등

2. 영속성 컨텍스트
- JVM 레벨의 Database
- 1차캐시
- 동일성보장
- 트랜잭션을 지원하는 쓰기지연
- 변경 감지
- 지연로딩
3. 동등성과 동일성
- 동등성은 equals, hashcode로 비교 가능
- 동일성은 jvm레벨에서의 주소로 비교 가능
@Test
void identity() {
final Station station1 = stations.save(new Station("잠실역"));
final Station station2 = stations.findByName("잠실역");
assertThat(station1 == station2).isTrue();
}
과연 동일함이 어떻게 보장이 되냐

영속 컨텍스트에서는 키값이 동일한것 2개이상있을 수 없음.
그렇기 때문에 영속성 캐시는 트랜잭션이 열릴때부터 닫힐때까지 유지

그리고 Service에 Transactional을 안붙어도 영속성 캐시가 되는데요? 라는 생각이들 수도 있다. 위에 보면 Repository에 @Transactional이 붙어있어서 그렇다. (추후 이 부분 때문에 트러블 슈팅이 필요할 때가 있음.)
JPA 동작 원리 개념

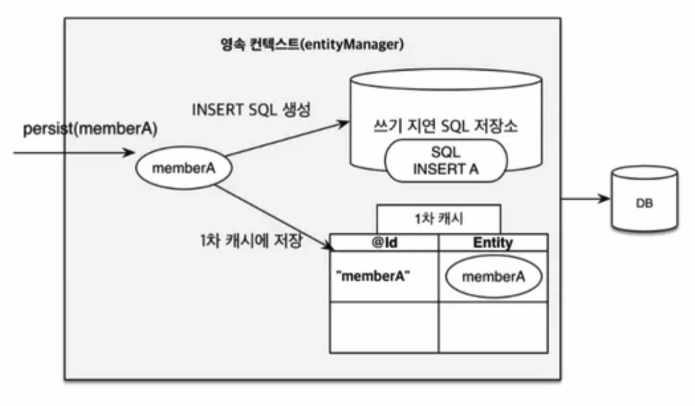
- 쓰기지연은 한번에 모아서 실행된다.
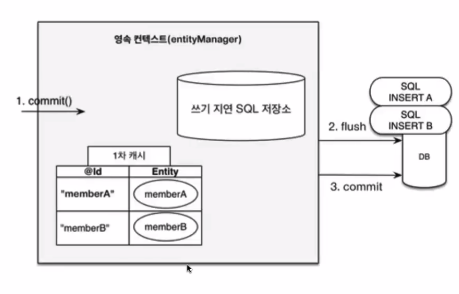
JPA 동작 원리 실습
1. Persistance

위에서는 왜 insert문이 실행되었을까?
-> ID가없으면 ID를 얻고자 쓰기지연과 상관없이 insert 쿼리 실행
-> 영속성 컨텍스트에서 관리하기위해서 ID는 필수이기 때문에
그러면 id @generate를 주석하고 생성자로 받으면?

insert는 안나가는데 select가 나가고 있다.
이유는? save할때, 영속성 컨텍스트에서 해당 값이 DB에 있는지 없는지 체크하려고 DB에 쿼리 날리것이다.
-> 있으면 Update, 없으면 Insert 실행을 위해서

isNew의 기준은? id가 null인지 아닌지
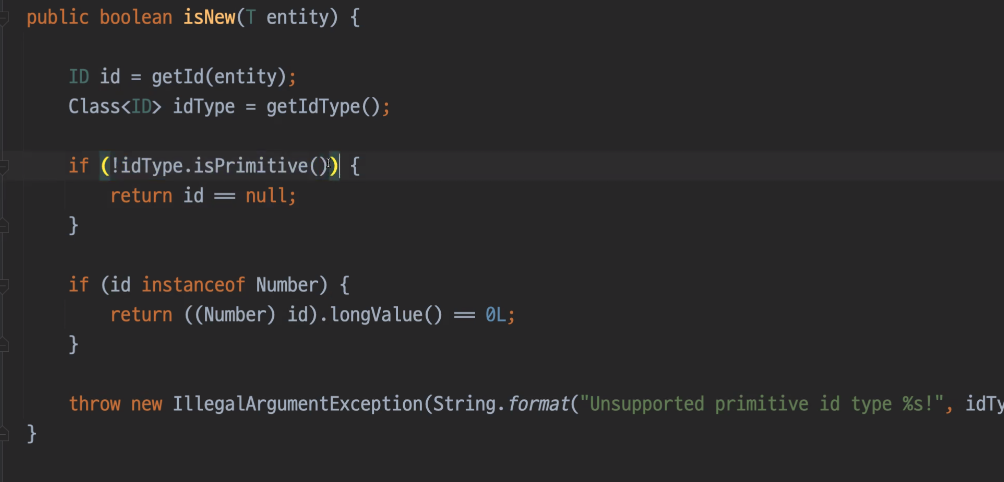
Persistable을 implement해서 isnew 사용하면 select query가 나가지 않도록 할 수 있다.
2. Dirty Checking

- 영속성 컨텍스트에 저장되었을때 스냅샷을 저장하고 있음
- 커밋됬을때 비교해서 달라진게 있으면 DB에 반영
@Test
void update() {
final Station station1 = stations.save(new Station("잠실역"));
station1.changeName("몽촌토성역");
station1.changeName("잠실역");
final Station station2 = stations.findByName("몽촌토성역");
assertThat(station2).isNotNull();
}위 처럼 코드짜면 업데이트 쿼리 안나간다 -> 스냅샷이 있기 때문
- dbms마다 readonly가 다다르다.
- 하이버네이트는 readonly 가 true면 스냅샷 생성 하지않는다.
- JVM 메모리상에서 조금이라도 효율이 있을 수 있으나 사실 힙메모리 그렇게 차지하지 않고 절약은 가능하다. (덤프는 힙메모리가 터져야 의미가있다고 생각)
3. 그 외 Persistence Context에 대해 알아두면 좋은 것들
영속성컨텍스트는 id를 기반으로 관리
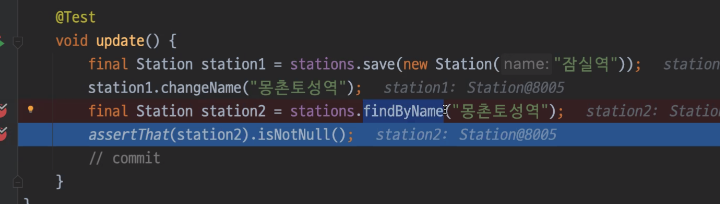
위 시점에서 이미 update & select query가 실행됨
why? -> ID기반으로 가져오는게 아니기 때문에 JPQL 작동 (JPQL 특징)
JPQL은 영속성 거치지않고 바로 db에 직접 query
-> JPQL이 동작할때는 무조건 flush 가 발생하는데, 이유는 영속성이 없으므로 flush를 발생하지 않으면 '몽촌토성역'을 찾을수가 없는상황이기 때문이다. (위 코드 참고)
참고로 @JpaTest 에는 @Transactional 이 포함되어있고, 똑똑해서 어차피 rollback할거라 쓰기지연을 하지 않는다.

- 그래서 테스트를 진행할 때, 쓰기지연되는 쿼리로그를 확인하고 싶으면 flush()를 강제호출 할 수 있다.
- (하지만, 우리가 가비지 컬렉션도 System.gc()를 선언하지 않는 것을 권장하듯이 flush 도 동일)
- TransactionManager, EntityManager를 통해서 flush(), clear() 사용가능.
프록시객체인지 디버깅 파악하는 방법은?

간단한 방법으로는 getName()으로 프록시인지아닌지 파악 가능하다.
'JPA.' 카테고리의 다른 글
| JPA 동시성 문제 해결하기 (feat. JMeter) (0) | 2022.09.13 |
|---|---|
| [Spring] JPA 동작 방식 (0) | 2022.02.02 |