문제 인식
회사에서 운영하고 있는 Telemetry 서비스는 1분 마다 각 장비의 모니터링 메시지를 받아서 파싱 및 저장하는 역할을 수행하고 있습니다.
해당 서비스는 원래 각 메시지를 개별적으로 처리하고, 이를 데이터베이스에 건별로 삽입하는 방식을 사용했습니다. 이 접근법은 단순하고 직관적이지만, 데이터 양이 급격하게 증가하면서 서비스 구조 변경이 필요했습니다.
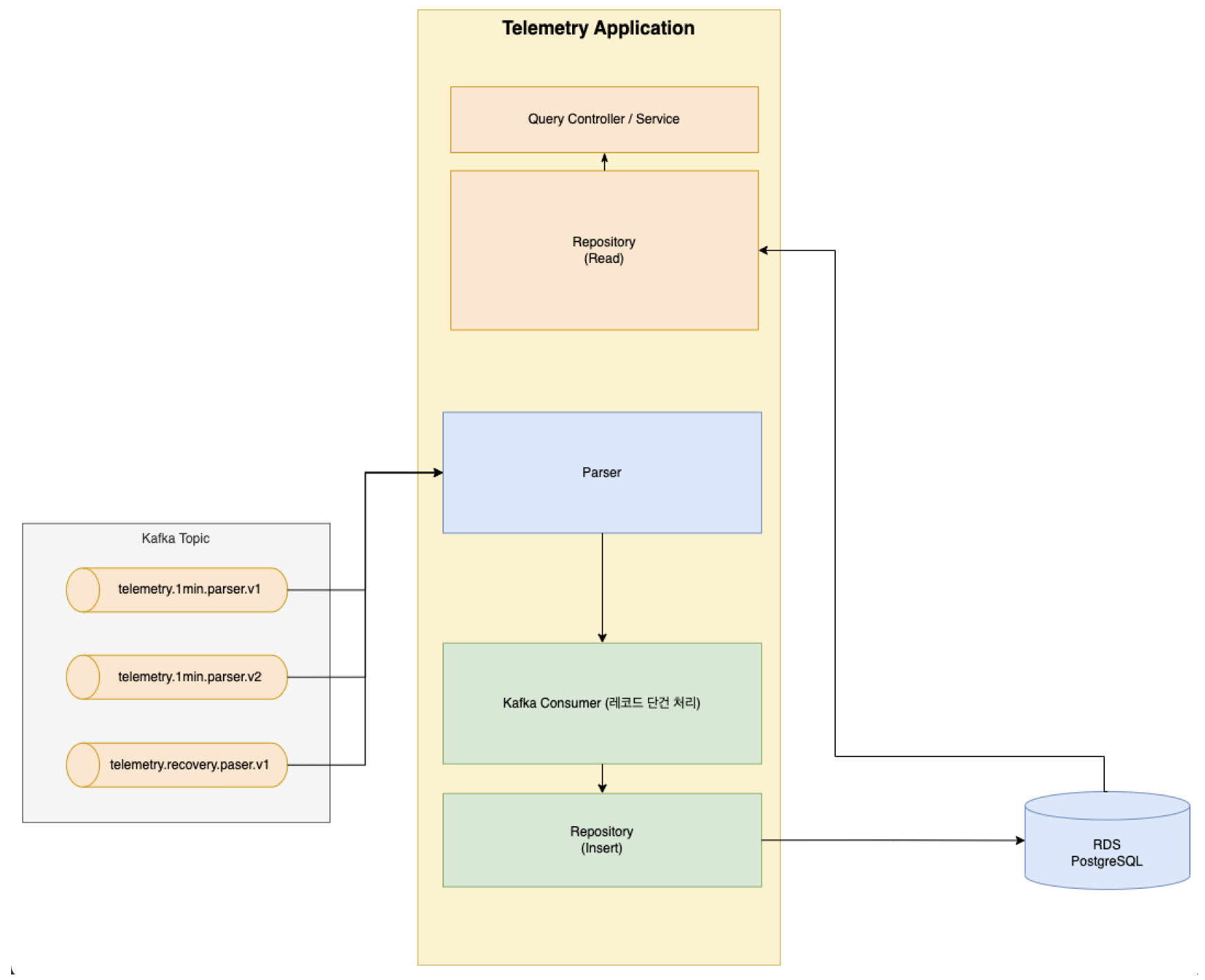
그래서 대용량 데이터를 처리하기 위해 다음과 같이 3가지 개선 전략을 적용했습니다.
개선 전략 1: Kafka Batch Listener 도입
처리 효율성을 높이기 위해 Kafka Batch Listener를 도입했습니다. 전통적인 Kafka Listener가 메시지를 개별적으로 처리하는 것과 달리, Batch Listener는 여러 메시지를 한 번에 처리할 수 있어 네트워크 오버헤드와 처리 지연을 줄일 수 있습니다.
Batch Listener 설정
1 2 3 4 5 6 7 8 9 10 | @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); var containerProperties = factory.getContainerProperties(); containerProperties.setAckMode(ContainerProperties.AckMode.TIME); containerProperties.setAckTime(10000); return factory; } | cs |
1 2 3 4 | @KafkaListener(topics = "topicName", containerFactory = "kafkaListenerContainerFactory") public void listen(List<ConsumerRecord<String, String>> records) { // TODO : 로직 구현 } | cs |
Kafka Consumer Config 설정
그 외에도 Kafka Batch Listener를 도입할 때 고려해야 할 주요 Kafka Consumer Config 옵션들은 다음과 같습니다. 이러한 설정들은 Kafka 메시지의 효율적인 배치 처리를 위해 조정될 수 있으며, 시스템의 성능과 처리량에 중요한 영향을 미칩니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | public ConsumerFactory<String, String> consumerFactory() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(ConsumerConfig.GROUP_ID_CONFIG, "example-group"); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 해당 설정 값들은, 성능 최적화를 위해 서비스 특성을 고려하여 변경하시면 됩니다. props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 500000); // fetch.min.bytes props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 3000); // fetch.max.wait.ms props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500); // max.poll.records props.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 1048576); // max.partition.fetch.bytes props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 10485760); // fetch.max.bytes props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 15000); // session.timeout.ms props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 5000); // heartbeat.interval.ms return new DefaultKafkaConsumerFactory<>(props); } | cs |
| fetch.min.bytes |
|
| fetch.max.bytes |
|
| max.poll.records |
|
| fetch.max.wait.ms |
|
| session.timeout.ms / heartbeat.interval.ms |
|
| max.partition.fetch.bytes |
|
이러한 설정들은 Kafka의 성능과 리소스 사용에 직접적인 영향을 미칩니다. 따라서, 배치 리스너를 사용할 때 이러한 설정을 적절히 조정하는 것이 중요합니다. 설정값은 사용 사례, 메시지 크기, 처리량 요구사항, 시스템 리소스 등에 따라 달라질 수 있기 때문에 모니터링을 통해 최적의 값을 찾는 것이 좋습니다.
개선 전략 2: Bulk Insert 전략 사용
데이터베이스 작업 성능을 개선하기 위해, 각 메시지를 개별적으로 삽입하는 대신 Bulk Insert 전략을 적용했습니다. Spring JDBC의 Bulk Insert 기능을 사용하여 여러 레코드를 단일 쿼리로 데이터베이스에 삽입함으로써, 데이터베이스 쓰기 작업의 횟수를 줄이고 전반적인 성능을 향상시켰습니다.
1 2 3 4 | public int[] save(List<Data> bulkData) { SqlParameterSource[] batch = SqlParameterSourceUtils.createBatch(bulkData.toArray()); return namedParameterJdbcTemplate.batchUpdate(SQL_INSERT_TELEMETRY_INFO), batch); } | cs |
개선 전략 3: 파티션 수 증가 대신 Concurrency & @Async 사용
Kafka에서 파티션 수를 늘리는 것은 다음과 같은 이슈들을 야기할 수 있습니다.
1. 브로커의 메모리 사용 증가
Kafka 브로커는 각 파티션에 대한 메타데이터를 메모리에 저장합니다. 파티션 수가 증가하면 이 메타데이터의 크기도 증가하여 브로커의 메모리 사용량이 늘어납니다.
2. 리더 선출과 리밸런싱 오버헤드
Kafka는 각 파티션에 대해 리더를 선출하고, 컨슈머 그룹 내에서 파티션을 리밸런싱합니다. 파티션 수가 많으면 이러한 작업이 더 자주 발생할 수 있으며, 이는 추가적인 오버헤드를 유발합니다.
3. 복제 지연
각 파티션은 여러 브로커에 복제됩니다. 파티션 수가 많을수록 복제할 데이터도 많아지기 때문에, 복제 지연을 증가시킬 수 있습니다.
4. 장애 복구 시간 증가
파티션이 많아지면 장애 발생 시 복구해야 할 데이터 양도 늘어나기 때문에, 전체 복구 시간을 길어지게 할 수 있습니다.
위와 같은 이슈들 때문에, Telemetry 서비스의 경우 시스템의 확장성과 관리 효율성을 고려하여 단순히 파티션 수를 증가시키는 대신에 동시성(Concurrency)과 @Async 어노테이션을 사용했습니다.
Concurrency 설정
1 2 3 4 5 6 7 8 9 10 11 | @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setConcurrency(2); var containerProperties = factory.getContainerProperties(); containerProperties.setAckMode(ContainerProperties.AckMode.TIME); containerProperties.setAckTime(10000); return factory; } | cs |
Async 설정 및 구현
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | @Configuration @EnableAsync public class AsyncConfig { @Bean(name = "taskExecutorBatch") public Executor taskExecutorBatch() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(3); executor.setMaxPoolSize(8); executor.setQueueCapacity(20); executor.setKeepAliveSeconds(120); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.setThreadNamePrefix("Async-Executor-Batch"); executor.initialize(); return executor; } @Bean(name = "taskExecutorParser") public Executor taskExecutorParser() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(3); executor.setMaxPoolSize(8); executor.setQueueCapacity(20); executor.setKeepAliveSeconds(120); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.setThreadNamePrefix("Async-Executor-Parser"); executor.initialize(); return executor; } } | cs |
1 2 3 4 5 | @Async("taskExecutorBatch") @Transactional public void saveAll(List<Data> bulkdata) { dao.saveAll(bulkdata); } | cs |
이렇게 Concurrency & Async 설정을 통해 파티션 수를 증가시키지 않고 애플리케이션 레벨에서의 스케일링하는 방법을 알아보았습니다. 애플리케이션 레벨에서의 스케일링은 Kafka 시스템의 구조적 변경 없이도 가능하기 때문에 Kafka를 효율적으로 관리할 수 있었습니다.
이러한 전략들의 도입으로 Telemetry 서비스는 하루에 수억 건의 데이터를 처리할 수 있는 서비스 아키텍처로 바뀌었습니다.
Kafka Batch Listener의 사용은 데이터 처리량이 많은 상황에서도 효율적인 메시지 처리를 가능하게 했으며, Bulk Insert 전략은 데이터베이스 쓰기 작업의 성능을 크게 향상시켰습니다. 또한, 파티션 수를 무작정 늘리는 대신 Concurrency와 @Async 어노테이션을 활용함으로써 시스템의 복잡성을 최소화하면서 처리 능력을 극대화했습니다.
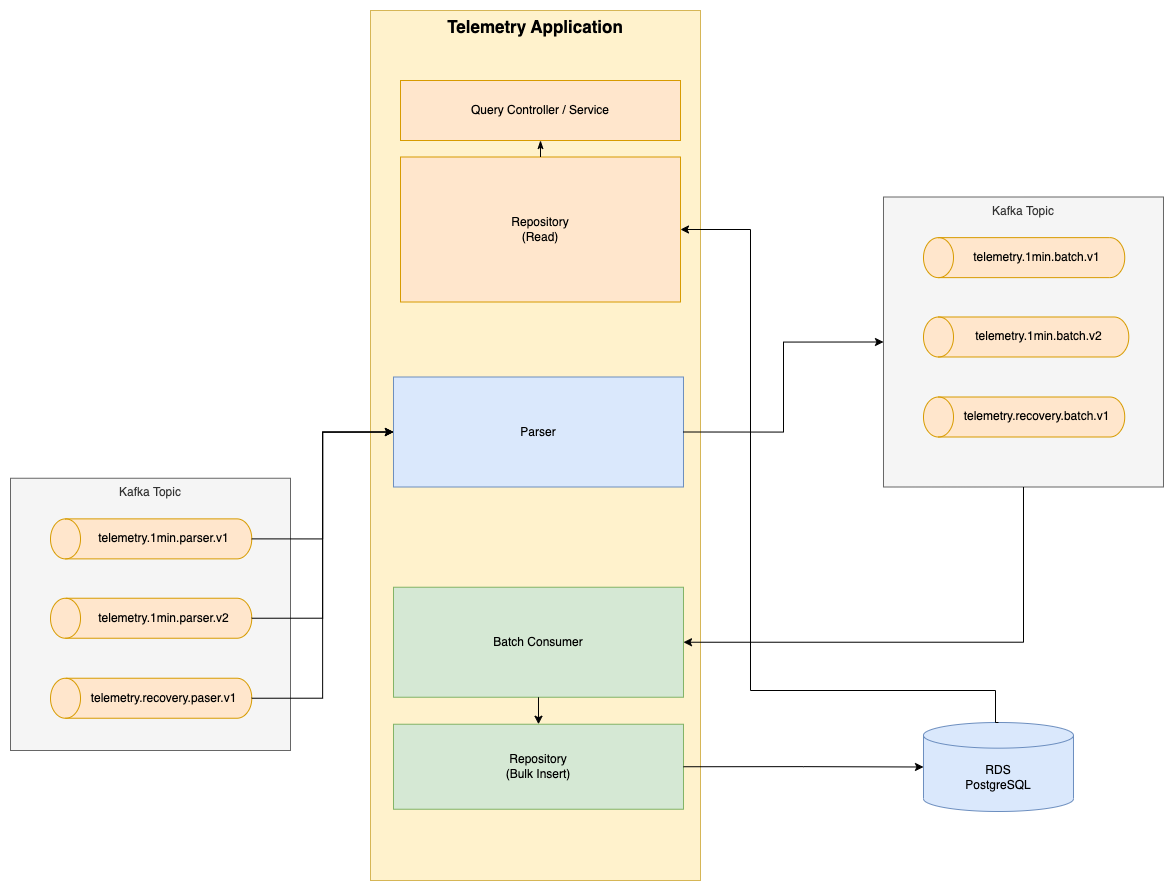
이러한 개선을 통해, Telemetry 서비스는 높은 처리량과 확장성을 요구하는 환경에서도 원활하게 작동할 수 있는 견고한 아키텍처를 갖추게 되었습니다.
미션 목표
- 1분마다 50만개 메시지 처리 (하루 누적 7억 2천개)
- 1개 Message 크기 : 5 KB
부하테스트 환경
| Kafka Broker |
|
| K8S Deployment |
|
| Timescale DB (EC2) |
|
'이슈 해결과정 기록' 카테고리의 다른 글
| 글로벌 서비스 운영을 위한 API 설계 방법 (feat. Timezone) (0) | 2022.11.14 |
|---|---|
| DST에 대해 알아보자 (0) | 2022.11.14 |